前言
之前也写过一些关于可视化的文章,比如:
[post cid="43" /]
[post cid="84" /]
不过都是比较基础的入门内容。最近在学量化,有位开发者整理了常见的量化图表,原文章,都是用matplotlib和seaborn做的。我个人还是更倾向于颜值高又可交互的plotly的,所以把他的代码改写为plotly。大多数能改成功,也有一些我不知道怎么实现的,只能搁置了,若有大神知道代码怎么写,欢迎评论区留言。
前置
首先导入相关库,并作相应的设置
import numpy as np
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import plotly.figure_factory as ff
import matplotlib.pyplot as plt
import plotly
plotly.offline.init_notebook_mode(connected=True)
# 这个是作图的初始设定,因为我嫌默认的字体太小了,所以改得大了些
layout = dict(title_x=0.5, # title居中
font=dict(family="Times New Roman",size=20,color="RebeccaPurple"),
# 字体设置
coloraxis_colorbar=dict(xanchor="left",x=0.75,ticks="outside"),
# 颜色条设置
margin=dict(b= 40,l=40, r=40, t= 40)
# 大小设置
)数据仍然使用原作者提供的美股5家上市公司日线数据,我手动下载下来又传到github上了,大家使用的时候可以下载原数据,或者直接读取远程连接。
github地址:https://github.com/caly5144/shu-s-project/tree/master/quan/visual
下面就是获取数据的代码,主要有两种,默认是只使用特斯拉的日线数据,后面作相关性热力图的时候会用到第二种数据,这里提前把数据整理了一下,由长格式数据转为宽格式数据。
def get_date(is_tesla=1):
df = pd.read_excel('data.xlsx')
# 也可以直接读取下面的远程连接,无需再手动下载数据了
#df = pd.read_csv('https://cdn.jsdelivr.net/gh/caly5144/shu-s-project/quan/visual/data.csv')
if is_tesla:
df = df[df['code']=='usTSLA']
df = df.reset_index()
else:
df = df[['time', 'code', 'p_change']]
df = df.pivot_table(index=["time"],columns=["code"],values=["p_change"])
df.columns = df.columns.droplevel(0)
df.index.name = None
df = df.reset_index().dropna()
df = df.rename(columns={'index':'time'})
print(df)
return df作图
价格与均线
首先是最简单的折线图,一般用于展示股票价格变化
代码
def plot(): # 普通折线图
df = get_date()
fig = px.line(df, x="time", y="close",title='tsla close').update_layout(layout)
plotly.offline.plot(fig)效果

当然也可以同时展示多个指标或股票,加个color=参数即可。
def price(): # 价格与均线
df = get_date()
for window in [30,60,90]:
df[str(window)+' mv'] = df['close'].rolling(window).mean()
df = df.melt(id_vars='time',value_vars=['close', '30 mv','60 mv','90 mv'])
fig = px.line(df, x="time", y="value", color="variable",labels={"variable": "指标"})\
.update_layout(layout)
fig.update_yaxes(visible=False, showticklabels=False)
plotly.offline.plot(fig)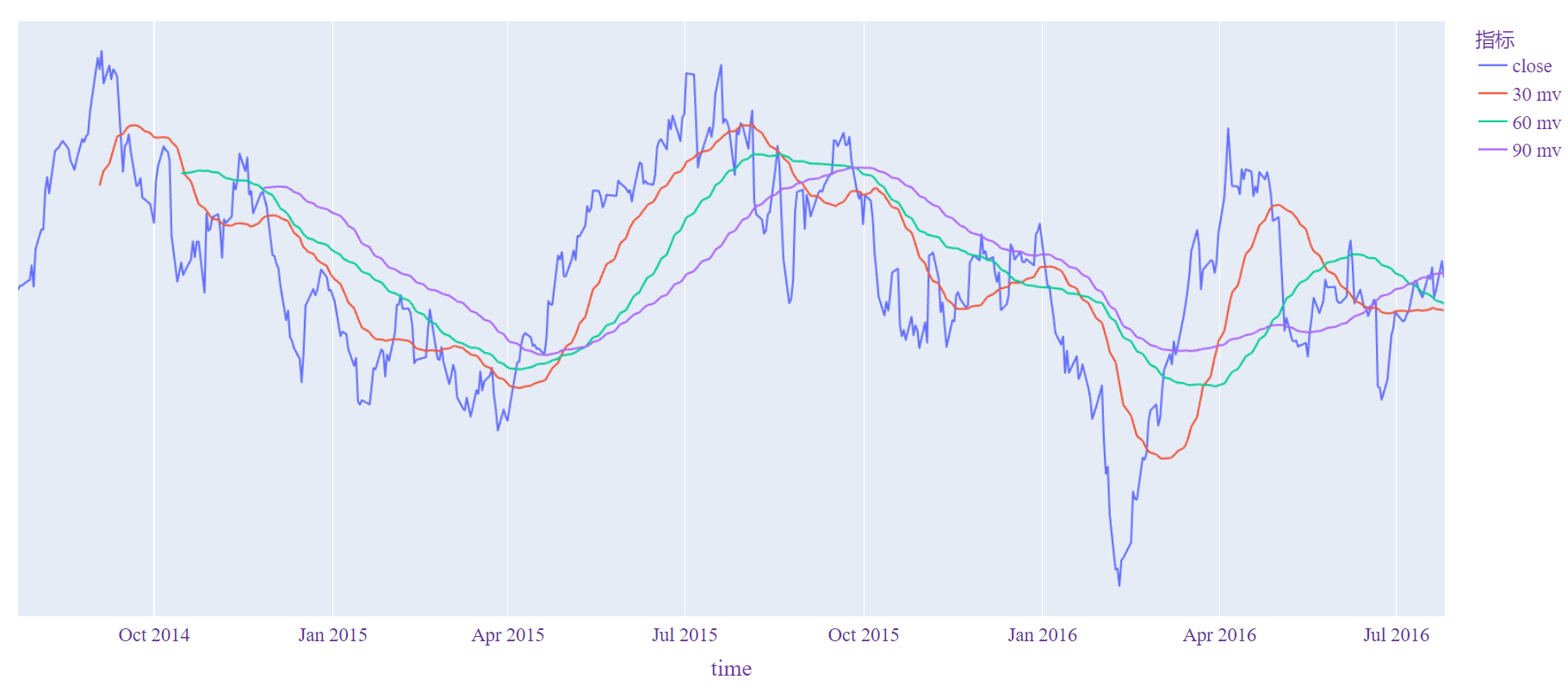
蜡烛图(K线图)
蜡烛图,也称K线图,是作技术分析时最常见的图
def candle(): # 蜡烛图
df = get_date()
df['ma_5'] = df['close'].rolling(5).mean() # 计算5日均线
#为了示例清晰,只拿出后30天的交易数据绘制蜡烛图
df = df[-30:]
fig = go.Figure(data=[go.Candlestick(x=df['time'],
open=df['open'],high=df['high'],
low=df['low'],close=df['close'],
increasing_line_color= 'red', # 上升是红色
decreasing_line_color= 'green' # 下降是绿色
,name = 'K线图')]).update_layout(layout)
#fig.update_layout(xaxis_rangeslider_visible=False) # 底部时间拖动条是否可见
fig.add_trace(go.Scatter(x=df.time, y=df.ma_5,name="5日均线"))
plotly.offline.plot(fig)
量价图
大家看股票的时候,除了关心价格外,还关心成交量,下面的代码就给出了如何将K线图与成交量展示在同一张图中。
def can_vol():# 量价图
df = get_date()
df['ma_30'] = df['close'].rolling(30).mean()
fig = make_subplots(rows=2, cols=1, shared_xaxes=True)
# shared_xaxes是否共享x轴
fig.append_trace({"type": "candlestick", "x": df['time'],
"low": df['low'],"high": df['high'],"open": df['open'],
"close": df['close'],"increasing_line_color": "red",
"decreasing_line_color":'green','name':'K线'},1,1)
fig.append_trace({'x':df.time,'y':df.ma_30,'type':'scatter','name':'30日均线'},1,1)
fig.append_trace({'x':df.time,'y':df.volume,'type':'bar','name':'成交量'},2,1)
fig['layout']['yaxis1'].update(domain=[0.2, 1])
fig['layout']['yaxis2'].update(domain=[0, 0.2])
# 上面代码用于调整两幅图的顺序以及各自大小(宽相同,高不同)
fig.update_layout(layout)
fig.update_layout(xaxis_rangeslider_visible=False) # 上方拖动条不可见
fig.update_layout(xaxis2_rangeslider_visible=True) # 展示最下方的时间拖动条
#fig.update_layout(showlegend=True)
plotly.offline.plot(fig)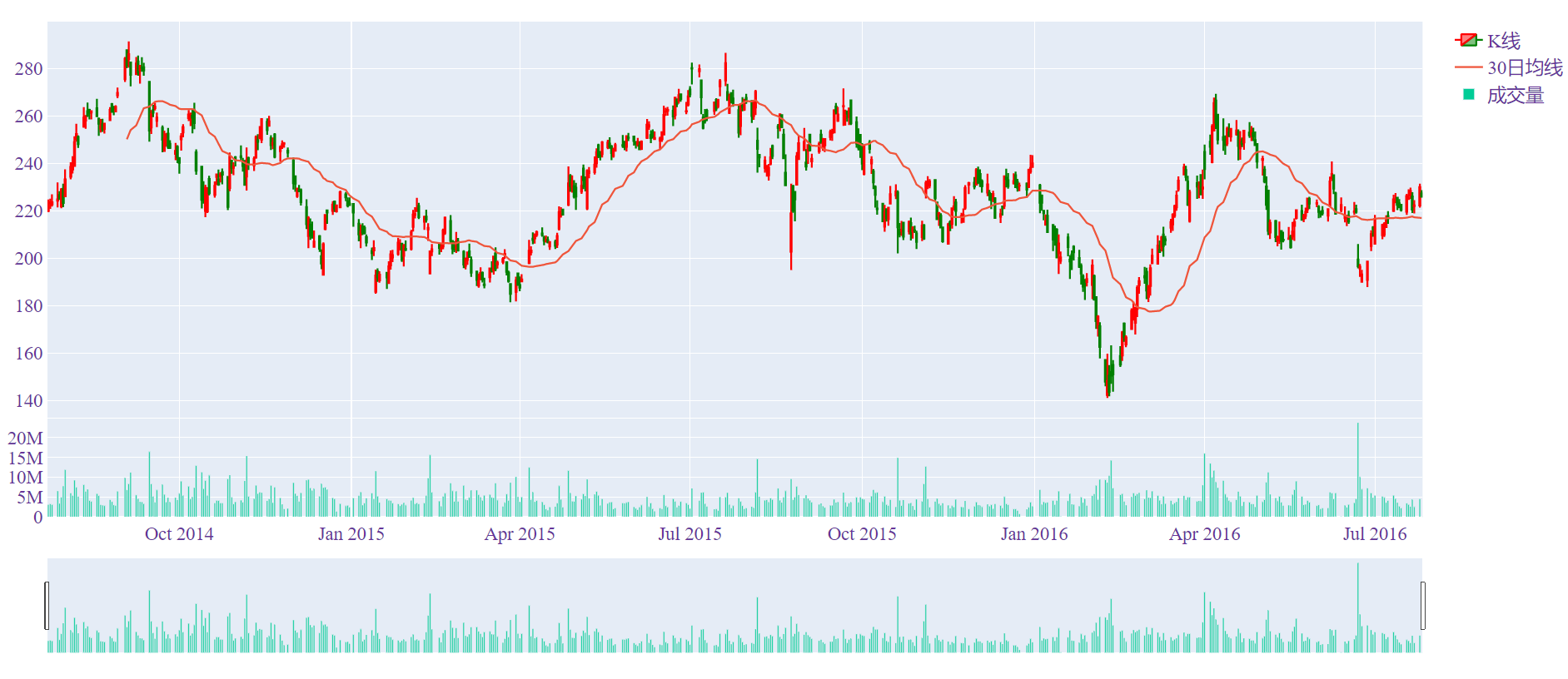
有些同学说,我想让它们放到一张图中,而不是以子图的形式展现,怎么做?
def candle_vol(): # 量价图
df = get_date()
df['ma_5'] = df['close'].rolling(5).mean()
trace1 = {
"name":"K线图","type": "candlestick",
"x": df['time'],"yaxis": "y2",
"low": df['low'],"high": df['high'],
"open": df['open'],"close": df['close'],
"decreasing": {"line": {"color": "red"}},
"increasing": {"line": {"color": "green"}}
}
trace2 = {
"name": "成交量", "type": "bar",
"x": df.time,"y": df.volume,"yaxis": "y",
"marker": {"color":"#6495ED"}
}
data = [trace1, trace2]
layout1 = {
"yaxis": {"domain": [0, 0.2], "showticklabels": False},
"yaxis2": {"domain": [0.2, 0.8]},
"legend": {
"x": 1,
"y": 0.8
},
}
layout.update(layout1)
fig = go.Figure(data=data, layout=layout)
plotly.offline.plot(fig)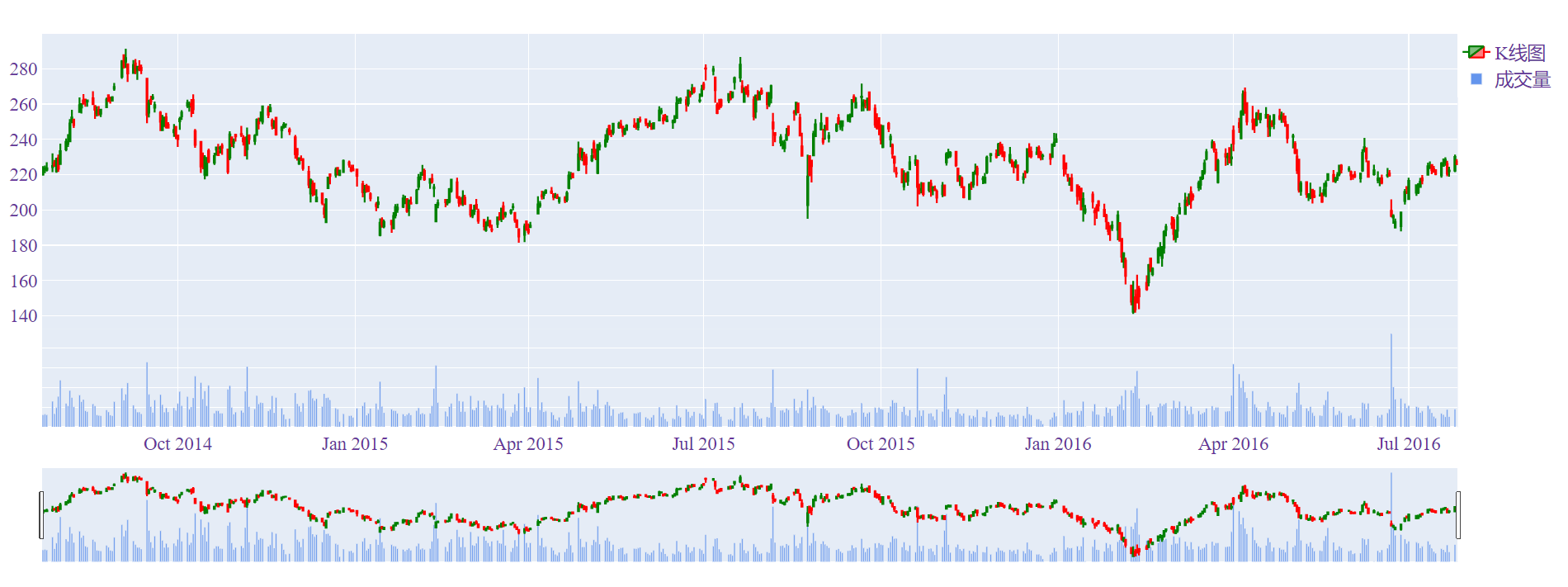
收益率与波动率图
由四个子图构成,列出了常见的收益率与标准差
def returns(): # 收益率与波动图
df = get_date()
# 投资回报
df['return'] = np.log(df['close'] / df['close'].shift(1))
# 移动收益标准差
df['mov_std'] = df['return'].rolling(20).std()* np.sqrt(20)
# 加权移动收益标准差,与移动收益标准差基本相同,只不过根据时间权重计算std
df['std_ewm'] = df['return'].ewm(span=20,min_periods=20, adjust=True).std()* np.sqrt(20)
fig = make_subplots(rows=4, cols=1)
alist = ['close', 'return','mov_std','std_ewm']
for item in alist:
fig.add_trace(
go.Scatter(x=df['time'], y=df[item],name=item),
row=alist.index(item)+1, col=1)
fig.update_layout(layout)
plotly.offline.plot(fig)
多类型子图
这幅图主要展示的是低开高走的交易日的下一个交易日的股票价格变化(我没明白这有什么用……),其实内容都一样,都是频率分布图,但我没办法在plotly上实现,所以直接照抄原作者的代码,用matplotlib了。
def subplot(): # 多类型子图
df = get_date()
# iloc获取所有低开高走的交易日的下一个交易日组成low_to_high_df,由于是下一个交易日
# 所以要对满足条件的交易日再次通过iloc获取,下一个交易日index用key.values + 1
# key序列的值即为0-len(tsla_df), 即为交易日index
low_to_high_df = df.iloc[df[(df.close > df.open) & (df.key != df.shape[0] - 1)].key.values + 1]
# 通过where将下一个交易日的涨跌幅通过ceil,floor向上,向下取整
change_ceil_floor = np.where(low_to_high_df['p_change'] > 0,
np.ceil(low_to_high_df['p_change']),
np.floor(low_to_high_df['p_change']))
# 使用pd.Series包裹,方便之后绘制
change_ceil_floor = pd.Series(change_ceil_floor)
_, axs = plt.subplots(nrows=2, ncols=2, figsize=(12, 10))
# 竖直柱状图,可以看到-1的柱子最高, 图5-7左上
change_ceil_floor.value_counts().plot(kind='bar', ax=axs[0][0])
# 水平柱状图,可以看到-1的柱子最长, 图5-7右上
change_ceil_floor.value_counts().plot(kind='barh', ax=axs[0][1])
# 概率密度图,可以看到向左偏移, 图5-7左下
change_ceil_floor.value_counts().plot(kind='kde', ax=axs[1][0])
# 圆饼图,可以看到-1所占的比例最高, -2的比例也大于+2,图5-7右下
change_ceil_floor.value_counts().plot(kind='pie', ax=axs[1][1])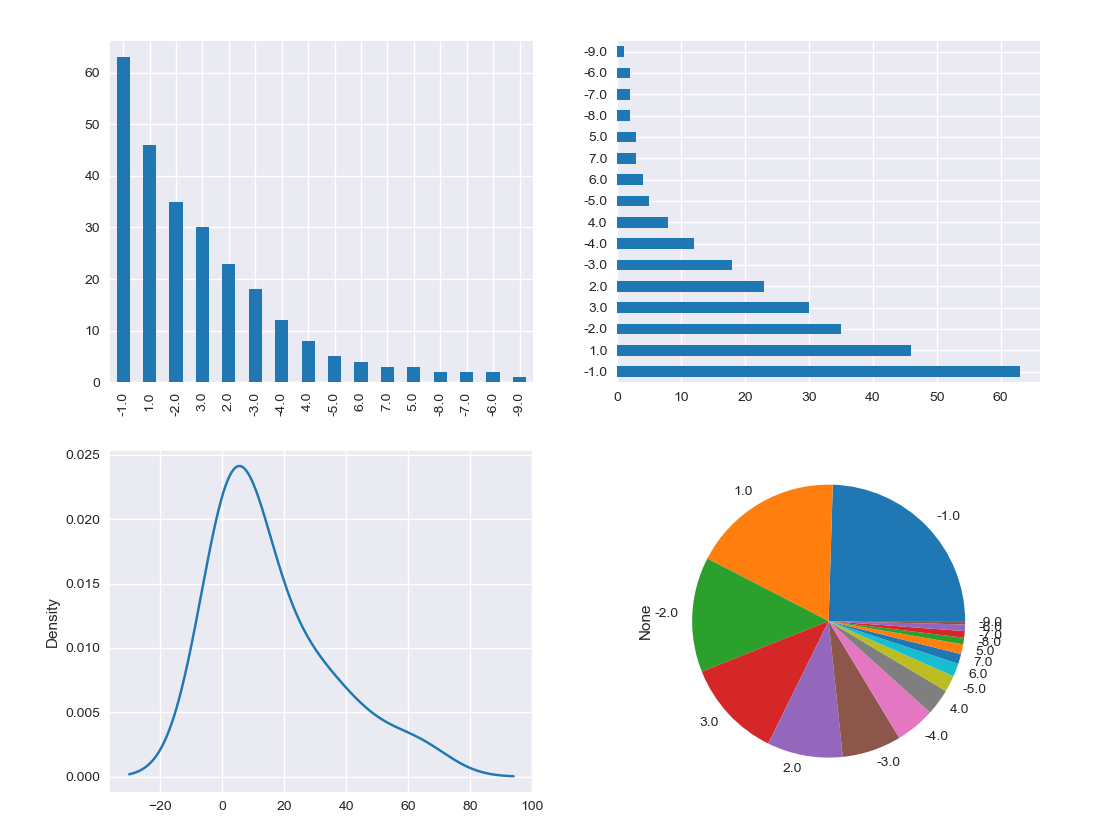
PS:我尝试了单独画频率分布直方图,但它没有办法像图中那样按高度降序排列,网上的资料说.update_xaxes(categoryorder="total descending")即可,但对我的图无效。箱型图
这张图展示了每周5个交易日的价格变化范围
def box(): # 箱型图
df = get_date()
fig = px.box(df, x="date_week", y="p_change", notched=False,color = 'date_week',
boxmode="overlay").update_layout(layout)
fig.update_layout(showlegend=False)
plotly.offline.plot(fig)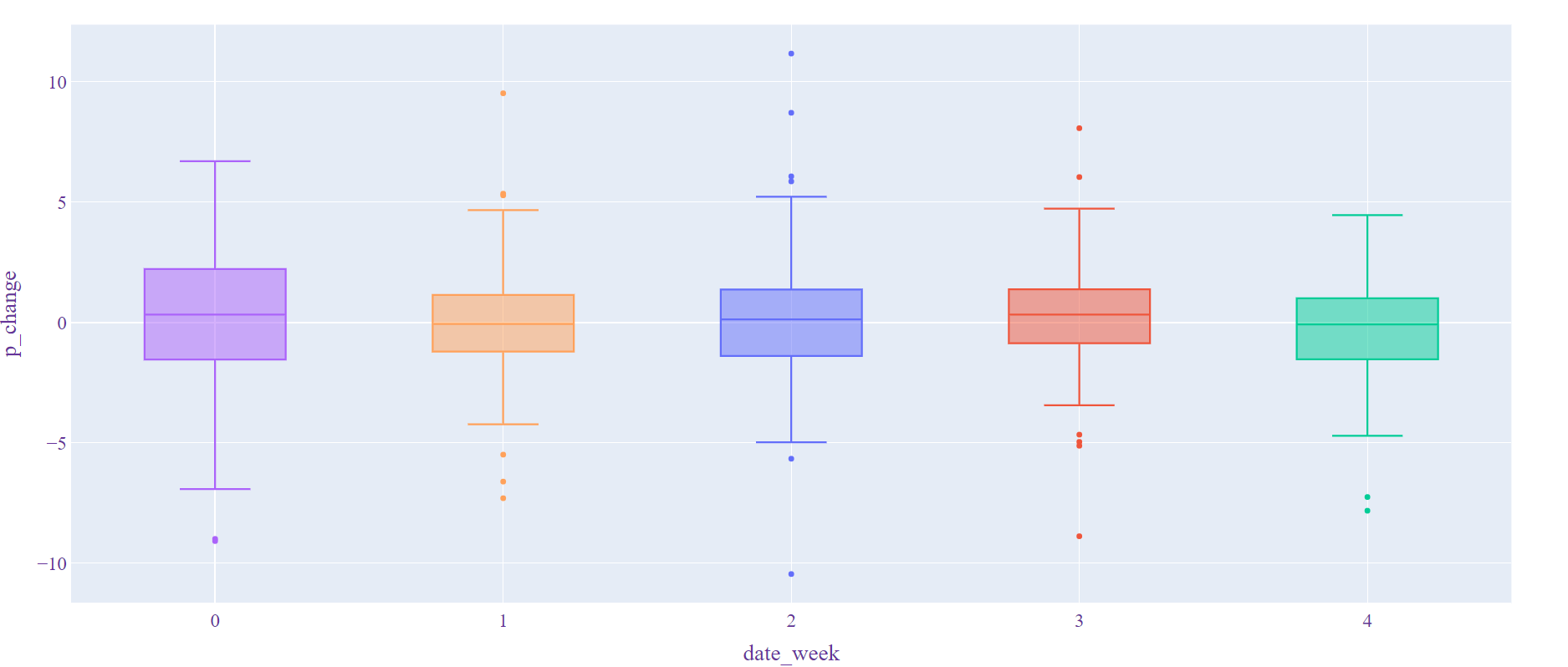
相关性热力图
该图展示了几只股票的相关性
def heat(): # 相关性热力图
df = get_date(is_tesla=0)
df = df.set_index('time')
corr = df.corr()
index_list = corr.index.tolist()
col_list = corr.columns.values.tolist()
fig = px.imshow(corr,x = col_list,y = index_list,color_continuous_scale='blugrn').update_layout(layout)
plotly.offline.plot(fig)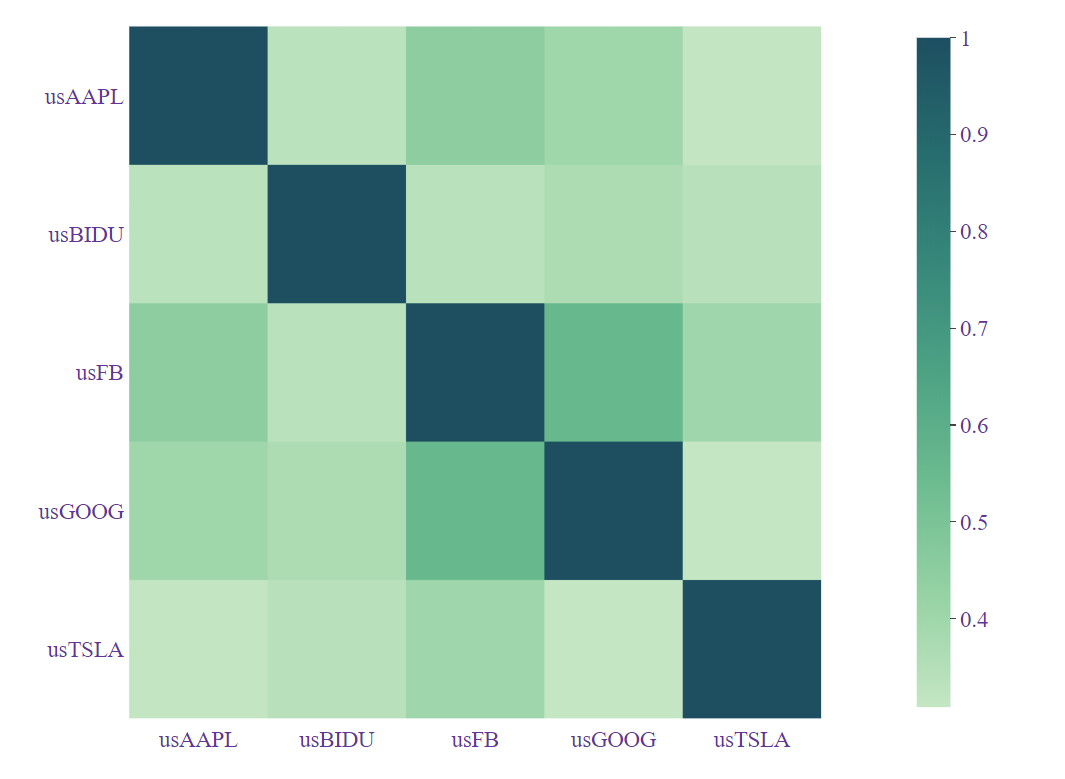
卖出原因
这幅图展示了股票持有期(绿色),以及卖出的原因
def sell_reseaon(buy_date,sell_date): # 卖出原因
df = get_date()
# 找出2014-07-28对应时间序列中的index作为start
start = df[df.time == buy_date].key.values[0]
# 找出2014-09-05对应时间序列中的index作为end
end = df[df.time == sell_date].key.values[0]+1
fig = px.line(df, x="time", y="close",color_discrete_map = {"close": "red"}).update_layout(layout)
fig.add_trace(go.Scatter(x=df.time, y=df.close, fill='tozeroy',fillcolor='rgba(0,0,255,0.08)'))
fig.add_trace(go.Scatter(x=df.time[start:end], y=df.close[start:end], fill='tozeroy',fillcolor='rgba(0,255,0,0.38)'))
#fill='tozeroy'是填充值x轴,tonexty是填充至另外一个trace,fillcolor是填充颜色,因为red,green之类的没法设定透明度,只能用rgba了
fig.update_layout(showlegend=False,annotations=[
dict(x='2014-09-05',y=df.close[end-1],
xref="x",yref="y",text="sell for stop loss",
showarrow=True,arrowhead=7,ax=0,ay=-40
)])
plotly.offline.plot(fig)
黄金分割线
这张图展示了几条黄金分割线
def gold(): # 黄金分割线
from scipy import stats
df = get_date()
cs_max = df.close.max()
# 收盘价格序列中的最小值
cs_min = df.close.min()
sp382 = (cs_max - cs_min) * 0.382 + cs_min
sp618 = (cs_max - cs_min) * 0.618 + cs_min
print('视觉上的382: ' + str(round(sp382, 2)))
print('视觉上的618: ' + str(round(sp618, 2)))
sp382_stats = stats.scoreatpercentile(df.close, 38.2)
sp618_stats = stats.scoreatpercentile(df.close, 61.8)
print('统计上的382: ' + str(round(sp382_stats, 2)))
print('统计上的618: ' + str(round(sp618_stats, 2)))
# 从视觉618和统计618中筛选更大的值
above618 = np.maximum(sp618, sp618_stats)
# 从视觉618和统计618中筛选更小的值
below618 = np.minimum(sp618, sp618_stats)
# 从视觉382和统计382中筛选更大的值
above382 = np.maximum(sp382, sp382_stats)
# 从视觉382和统计382中筛选更小的值
below382 = np.minimum(sp382, sp382_stats)
df['above618'] = above618
df['below618'] = below618
df['above382'] = above382
df['below382'] = below382
df = df.melt(id_vars='time',value_vars=['close', 'above618','below618','above382',
'below382'],var_name='指标')
fig = px.line(df, x="time", y="value",color='指标').update_layout(layout)
plotly.offline.plot(fig)
版权属于:作者名称
本文链接:https://www.sitstars.com/archives/94/
转载时须注明出处及本声明